이번 시간에는 DataFrame을 다루는 방법에 대해서 공부하려한다.
1. Index삽입
2. 행렬 Transpose
3. DataFrame의 Data 특정 행과 열의 데이터 변경
4. 새로운 Feature 생성
Index삽입

지난 시간에 생성하고 저장한 DataFrame을 호출한 사진이다.
이 DataFrame을 보면 짱구는 이름이라고 추측할 수 있지만 5와 500, 흰둥이는 무엇을 뜻하는지 파악하기 어렵다.
이에 대한 정보를 추가해주기 위해서 Index를 삽입하여 Data의 정보를 명시해준다.

df.index = ['이름','나이','용돈', '애완동물이름(없으면0)']
df
행렬 Transpose
또한 데이터를 위에서 아래로 읽는 것이 아닌 책과 같이 좌에서 우로 읽고 싶으면 행과 열을 Transpose해주는 방법을 사용하여 행과 열을 바꿔준다.
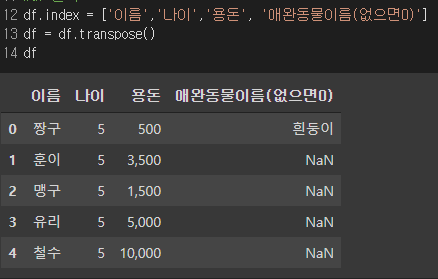
df.index = ['이름','나이','용돈', '애완동물이름(없으면0)']
df = df.transpose()
df
DataFrame의 Data 특정 행과 열의 데이터 변경
DataFrame의 특정 구역의 데이터를 수정하고 싶다면 어떻게 해야할까? loc 과 iloc을 사용 하면 된다.
loc : label을 통해서 값을 찾는다
iloc : integer position을 통해 값을 찾는다.
사용 예제
,
| loc | iloc | |
| 기능 | Label을 통해 값을 탐색 | Integer Position을 통해 값을 탐색 |
| 사용예시 | df.loc[[행],[열]] | df.iloc[[행],[열]] |
| 사용데이터 |  |
|
| 사용법 |
열을 바꾸는 법
df.loc[0:1, 0:] = 0 df.loc[0:1, ['이름','나이','용돈', '애완동물이름 =>A행(0번째 행)이 0으로 바뀜 (index, label)
=> '짱구'가 0으로 바뀜 (label, index)
|
열을 바꾸는 법
df.iloc[0:1, 0:] = 0
|
Tip. 다른 방법
df['이름'] = 0 : 특정 열의 데이터를 바꾸는 법
df['이름']['A'] = 0 : 특정 행, 열의 데이터를 바꾸는 법
새로운 Feature 생성
DataFrame의 정보로 새로운 Feature 생성
이 과정을 넘어가기 전에 일단 한가지 알아야 할 점이 있다.
1) 3,500은 실수형, 정수형이 아니기 때문에 연산이 불가능하다.
2) 강제적인 실수형, 정수형 변환은 ','문자 때문에 불가능하다.
-> ','를 제거하고 실수형 or 정수형으로 변환후에 계산한다.
이를 함수로 정의하여 사용하면 편리하다.
',' 를 제거하는 법 : replace를 사용한다.
str.replace('A','B') : 문자열의 'A'를 'B'로 바꾼다.
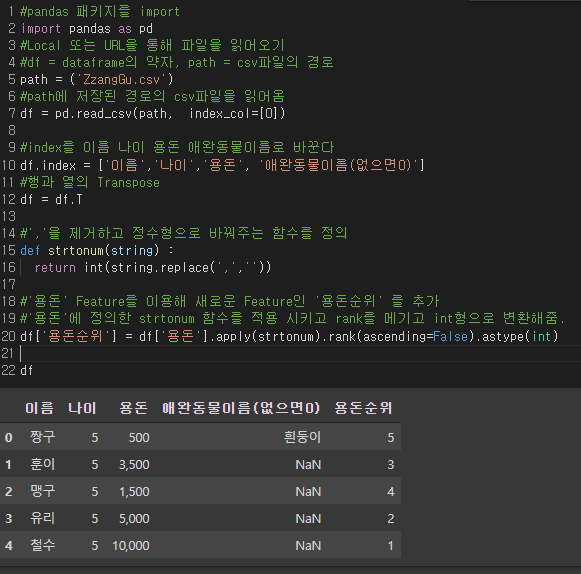
#index를 이름 나이 용돈 애완동물이름로 바꾼다
df.index = ['이름','나이','용돈', '애완동물이름(없으면0)']
#행과 열의 Transpose
df = df.T
#','을 제거하고 정수형으로 바꿔주는 함수를 정의
def strtonum(string) :
return int(string.replace(',',''))
#'용돈' Feature를 이용해 새로운 Feature인 '용돈순위' 를 추가
#'용돈'에 정의한 strtonum 함수를 적용 시키고 rank를 메기고 int형으로 변환해줌.
df['용돈순위'] = df['용돈'].apply(strtonum).rank(ascending=False).astype(int)
df
종합문제

위의 사진은 신발 매장 창고의 신발의 [브랜드, 제품명, 가격, 사이즈] 리스트이다.
위와 같은 데이터를 생성하고
(참고로 데이터 안에 들어가는 내용은 랜덤하게 들어간다. 단! 브랜드에 따른 제품명과 가격은 섞이지 않아야한다. ex) 반스 - 볼트 - 115,000 (0), 반스 - 볼트 - 69,000(x), 반스 - 에어맥스 - 69,000(x))
아래는 데이터를 생성할때 사용하는 기준표이다.
| 브랜드 | 제품명 | 가격 | 사이즈 |
| 나이키 | 테일윈드79 | 109,000 | 220~280 |
| 에어맥스 | 143,200 | ||
| 에어포스 | 109,000 | ||
| 아디다스 | 이지부스트 | 289,000 | |
| 독일군 | 139,000 | ||
| 슈퍼스타 | 75,900 | ||
| 컨버스 | 척테일러70(로우) | 89,000 | |
| 척테일러70(하이) | 92,000 | ||
| 런스타하이크 | 218,000 | ||
| 반스 | 올드스쿨 | 75,000 | |
| 볼트 | 115,000 | ||
| 스타일36 | 69,000 |
Tip) 브랜드가 key가 되고 제품명은 value가 된다. 또 다시 제품명은 key가 되고 가격은 value가 된다.
import pandas as pd
import random
shoes = {
'나이키' : {
'테일윈드79' : '109,000',
'에어맥스': '143,200',
'에어포스' : '109,000'
},
'아디다스':{
'이지부스트': '289,000',
'독일군':'139,000',
'슈퍼스타':'75,900'
},
'컨버스':{
'척테일러70(로우)' : '89,000',
'척테일러70(하이)': '92,000',
'런스타하이크': '218,000'
},
'반스':{
'올드스쿨' : '75,000',
'볼트': '115,000',
'스타일36': '69,000'
}}
dataframe = pd.DataFrame( index = [0], columns= ['브랜드', '품명', '가격', '사이즈'])
for x in range(0,3000):
dataframe.loc[x ,'브랜드'] = list( shoes.keys() )[ random.randint(0,3) ]
dataframe.loc[x ,'품명'] = list(shoes[ dataframe.loc[x ,'브랜드'] ].keys() )[ random.randint(0,2)]
dataframe.loc[x ,'가격'] = shoes[dataframe.loc[x ,'브랜드']][ dataframe.loc[x ,'품명']]
dataframe.loc[x ,'사이즈'] = random.randint(22,27) * 10 + random.randint(0,2) * 5
dataframe위 코드의 결과는 처음에 보여준 결과와 같을 것이다.
그렇다면 loc의 x의 위치를 바꿔주면 어떻게 될까?
import pandas as pd
import random
#이중 Dictionary로 data를 생성
shoes = {
'나이키' : {
'테일윈드79' : '109,000',
'에어맥스': '143,200',
'에어포스' : '109,000'
},
'아디다스':{
'이지부스트': '289,000',
'독일군':'139,000',
'슈퍼스타':'75,900'
},
'컨버스':{
'척테일러70(로우)' : '89,000',
'척테일러70(하이)': '92,000',
'런스타하이크': '218,000'
},
'반스':{
'올드스쿨' : '75,000',
'볼트': '115,000',
'스타일36': '69,000'
}}
dataframe = pd.DataFrame( columns = [0], index= ['브랜드', '품명', '가격', '사이즈'])
for x in range(0,3000):
dataframe.loc['브랜드',x] = list( shoes.keys() )[ random.randint(0,3) ]
dataframe.loc['품명',x] = list(shoes[ dataframe.loc['브랜드',x] ].keys() )[ random.randint(0,2)]
dataframe.loc['가격',x] = shoes[dataframe.loc['브랜드',x]][ dataframe.loc['품명',x]]
dataframe.loc['사이즈',x] = random.randint(22,27) * 10 + random.randint(0,2) * 5
dataframe
결과는 이렇게 된다. pd.DataFrame을 선언할때 index와 columns를 바꾸고, loc의 index 및 value의 위치를 바꾸자 데이터가 표의 가로로 추가되는 형태가 되었다. 이를 처음 결과와 같이 바꿔주기 위해서는 앞서 설명한 Transpose를 사용하면 된다.
dataframe = dataframe.T
dataframe
위의 코드를 추가하여 실행해보았다. DataFrame을 생성해서 Data를 넣을때 항상 랜덤한 값이 들어가기 때문에 데이터의 내용은 달라졌지만 행과 열의 위치가 바뀐 것을 알 수 있다.
위의 데이터는 생성할때마다 변경 되기 때문에 이후의 공부에 혼란을 초래하지 않도록 csv로 저장하여 계속해서 사용하도록 하자.
데이터 명은 'Shoes.csv'로 지정하였다.
다음은 10%의 할인률을 적용하여 아래와 같이 할인가를 표시해보도록하자.

이때 주의해야할 점은 가격은 문자이고 계산을 하기 위해서는 숫자로 바꿔야한다는 것이다.
문자를 숫자로 바꾸기 전에 ','과 같은 문자는 미리 제거해야한다.
import pandas as pd
import random
#import re
df = pd.read_csv('Shoes.csv', index_col= [0])
def StrToNum(string) :
return int(string.replace(',',''))
#def StrToNum(string) :
# return int(re.sub(',', '', string))
df['할인가'] = round(df['가격'].apply(StrToNum) - df['가격'].apply(StrToNum)/ 10,0).astype(int)
df위의 df['가격'].apply(StrToNum)/ 10,0).astype(int) 부분에서 apply는 ()안에 들어가는 커스텀 함수를 DataFrame에 적용히시키는 함수이다.
다음시간에는 브랜드 별 할인율을 다르게 적용하여 할인액을 구하고, 같은 제품 & 사이즈별로 묶어 중복되는 행을 삭제하고 재고 수로 표시하는 방법을 배우겠다.
'CodeStates' 카테고리의 다른 글
| [통계] #2 (0) | 2021.03.14 |
|---|---|
| [통계] #1 (0) | 2021.03.14 |
| [Python] 데이터 시각화 (0) | 2021.03.12 |
| [Pandas] DataFrame 생성, 저장 및 로드 (0) | 2021.03.08 |
| Git과 GitHub 그리고 Colab (0) | 2021.03.08 |


