#1
- Vector & Matrix Caluclation
- Unit Vectors
- Identity Matrix
- Determinant
- Inverse matrix
- 벡터와 매트릭스의 기본 연산
- Span, Basis, Rank
- Linear Projection
#2
- 분산과 표준편차
- 공분산
- 상관계수
- Vector Transformation
- EigenVector , EigenValue
- PCA
- High dimension Data와, 이로 인한 이슈
- Feature Extraction / Selection
#3
- Scree Plot
- Supervised / Unsupervised Learning
- K-means clustering
PCA
PCA : 주성분 분석이라는 뜻으로 여러 차원의 데이터에서 주요한 부분만을 차원 축소하는 기법을 말한다.
원래 고차원 데이터의 정보(==분산)를 최대한 유지하는 벡터를 찾고, 해당 벡터에 대해 데이터를 Linear Projection한다.
그렇다면 몇번째 주 성분까지 필요할까?
Scree Plot
이를 결정하기 위해 보통 아래와 같은 Scree Plot 이라는 것을 사용한다.
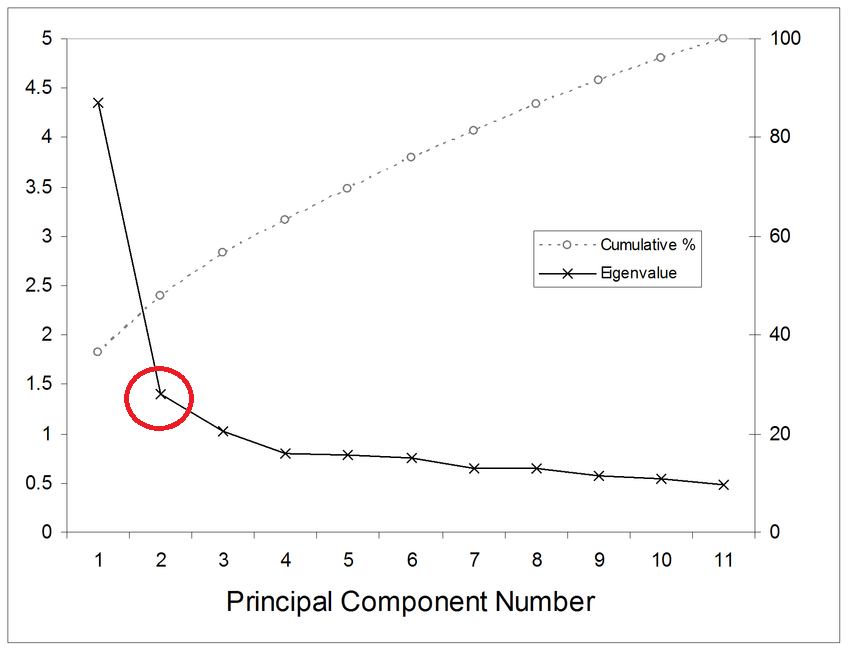
기울기가 심하게 꺽이는 부분 까지는 각 주성분이 데이터에서 차지하는 비중이 크지만, 꺽이는 부분 이후로는 주성분을 포함시켜도 차지하는 비중이 현저히 적어져 보통 기울기가 큰 지점(빨간색 지점)까지만 포함시킨다.
머신러닝 [ Supervised Learning : 지도학습] [Unsupervised Learning : 비지도 학습] []
머신러닝에서 지도 학습
: 트레이닝 데이터에 Label(답)이 있을때 사용할 수 있다.
분류 (Classfication) : 주어진 데이터의 클래스 예측을 위해 사용
회귀 (Prediction) : Continuous한 데이터를 바탕으로 결과 예측을 위해 사용.
머신러닝에서 비지도 학습
: Clustering 데이터의 연관된 Feature를 바탕으로 유사한 그룹을 생성.
기타 방법 :
차원축소 방법 [Association Rule Learning]: 높은 차원을 갖는 데이터셋을 사용하여 feature selection / extraction 등을 통해 차원을 줄이는 방법입니다.
연관 규칙 학습 : 데이터셋의 Feature간의 관계를 발견하는 방법.
강화 학습 [Reinforcement Learning]: 좋은 행동에 대해서는 보상, 그렇지 아니라는 행동에는 처벌을 통해 행동 학습을 함.
Clustering
비지도 학습의 한 종류.
데이터 셋을 요약하고 정리하는데에 있어서 효율중인 방법 중 하나이지만 정답을 보장하지 않기 때문에 예측을 위한 모델링 보다는 EDA를 위한 방법으로 주로 사용.
Clustering 종류
Hierarchical |
Point Assignment |
Hard vs Soft Clustering |
|
Agglomerative: |
시작시에 cluster의 수를 정하고 |
Hard Clustering에서 데이터는 하나의 cluster에만 할당. Soft Clustering에서 데이터는 여러 cluster에 확률을 가지고 할당. |
일반적으로 Hard Clustering을 Clustering이라고 한다.
Similarity
- Euclidean -> 주로 사용하는 방법.
- Cosine
- Jaccard
- Edit Distance
- Etc
K-Means Clustering
: n차원의 데이터에 대해 데이터중 랜덤으로 k개를 Cluster의 중심점으로 설정하고 해당 Cluster에 인접한 데이터를 Cluster로 할당한다. 그 후 변경된 CLuster에 대해 새로운 중심점으로 계산하여 지정한다. Cluster에 유의미한 변화가 없을때까지 반복한다. -> 중심점 선택 값에 있어 결과가 안좋을 수도 있고 계속해서 반복해야할 수도 있다.
->K-Means 방법 말고도 다양한 방법들이 존재하며, 최적의 방법을 선택하기 위해서는 결국 데이터에 대한 이해 즉, 도메인에 대한 지식이 있어야 좋은 방법을 선택할 수 있다.
중심점 계산법은 점들의 중심값을 계산하여 지정하는 방법과 랜덤한 값을 지정하는 방법이 있다.
k값을 결정하는 방법으로는 사람이 주관적인 판단을 하여 임의로 정하는 방법인 The Eyeball Method와
객관적인 지표를 설정해 최적의 K를 설정하는 Mertrics 방법이 있다.